
트위티의 열하일기
실전 데이터 분석 프로젝트 본문
#01 '한국복지패널데이터' 분석
1. 패키지 설치 및 로드
- foreign 패키지: SPSS, SAS, STATA 등 다양한 통계분석 소프트에어의 파일 불러올 수 있음
install.packages("foreign") # foreign 패키지 설치
library(foreign) # SPSS 파일 불러오기
library(dplyr) # 전처리
library(ggplot2) # 시각화
library(readxl) # 엑셀 파일 불러오기기
2. 데이터 불러오기
- read.spss(file = "파일이름", to.data.frame = T) : 데이터 불러오기
* to.data.frame = T : SPSS 파일을 데이터 프레임 형태로 변환하는 기능 → 이 파라미터가 없으면 데이터를 리스트 형태로 불러옴
3. 데이터 검토하기
head(welfare) # 데이터의 앞부분 일부 출력 (기본 6행)
tail(welfare) # 데이터의 뒷부분 일부 출력 (기본 6행)
View(welfare) # 데이터프레임을 별도 창에서 보기
dim(welfare) # 데이터의 차원 출력 (행, 열 개수 확인)
str(welfare) # 데이터 구조 출력 (변수 타입 및 샘플 값 확인)
summary(welfare) # 변수별 기초 통계량 요약 출력 (최소, 최대, 평균, 중앙값 등)
4. 변수명 바꾸기
- 코드북을 참고하여 분석에 어떤 변수를 활용할 것인지, 분석 방향에 대한 아이디어를 얻음
- 분석에 사용할 7개 변수의 이름을 쉬운 단어로 바꿈
welfare <- rename(welfare,
sex = h10_g3,
birth = h10_g4,
marriage = h10_g10,
religion = h10_g11,
income = p1002_8aq1,
code_job = h10_eco9,
code_region = h10_reg7)
5. 데이터 분석
- 변수 검토 및 전처리
- 변수 간 관계 분석

#02 성별에 따른 월급 차이 분석
성별에 따라 월급 차이가 있는가?

1. '성별' 변수 전처리 작업
class(welfare$sex) # 변수의 타입(자료형) 확인
table(welfare$sex) # 변수의 각 값별 빈도수 계산하여 출력
- 데이터에 이상치가 있는지 검토 및 이상치 부여
- 1과 2만 있고 9 또는 그 외의 값은 존재하지 않음
- 이 데이터의 경우, 이상치 없음 → 이상치 결측처리 과정은 건너뛰기
*이상치가 발견되었을 때 결측 처리하는 과정:
# 이상치 결측 처리;
welfare$sex <- ifelse(welfare$sex == 9, NA, welfare$sex)
# 결측치 확인
table(is.na(welfare$sex))
- 변수 이름을 이해하기 쉬운 이름으로 변경
# 성별 항목 이름 부여
welfare$sex <- ifelse(welfare$sex == 1, "male", "female")
# table()과 qplot()을 이용해 변경 사항이 반영됐는지 확인
table(welfare$sex)
qplot(welfare$sex)
2. '월급' 변수 전처리 작업
- 범주 변수인 성별 변수와 달리 월급 변수는 연속 변수 → table() 사용하면 너무 많은 항목이 출력됨
- 연속 변수는 summary()로 요약 통계량을 확인해야 특징 파악 가능
class(wefare$income) # 변수 타입 확인
summary(welfare$income) # 통계량 확인
qplot(welfare$income) # 분포 확인

- 데이터의 대다수를 차지하는 0~1000 사이의 데이터가 잘 표현되도록 설정 → xlim() 사용
qplot(welfare$income) + xlim(0, 1000)
- 결측치 및 이상치 처리


- summary() 출력 결과에 최솟값이 0으로 나타났지만 코드북에는 1~9998 사이의 값을 지닌다고 되어 있음
- 값이 0이거나 9999이면 결측 처리
- 다음 단계에서부턴 결측치를 제외하고 분석
# 이상치 결측 처리
welfare$income <- ifelse(welfare$income %in% c(0, 9999), NA, welfare$income)
# income 값이 0 또는 9999이면 NA(결측치)로 변환하고, 그렇지 않으면 기존 값을 유지
# 결측치 확인
table(is.na(welfare$income))
3. 변수 간 관계 분석하기
- 성별 월급 평균표 생성
sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(sex) %>%
summarise(mean_income = mean(income))
sex_income
- 성별 월급 평균표를 사용하여 막대 그래프 만들기
ggplot(data = sex_income, aes(x = sex, y = mean_income)) + geom_col()
#03 나이와 월급의 관계 분석
나이에 따라 월급이 어떻게 다른가?

1. 변수 검토 및 전처리
- 태어난 연도 검토
class(welfare$birth)
summary(welfare$birth)
qplot(welfare$birth)
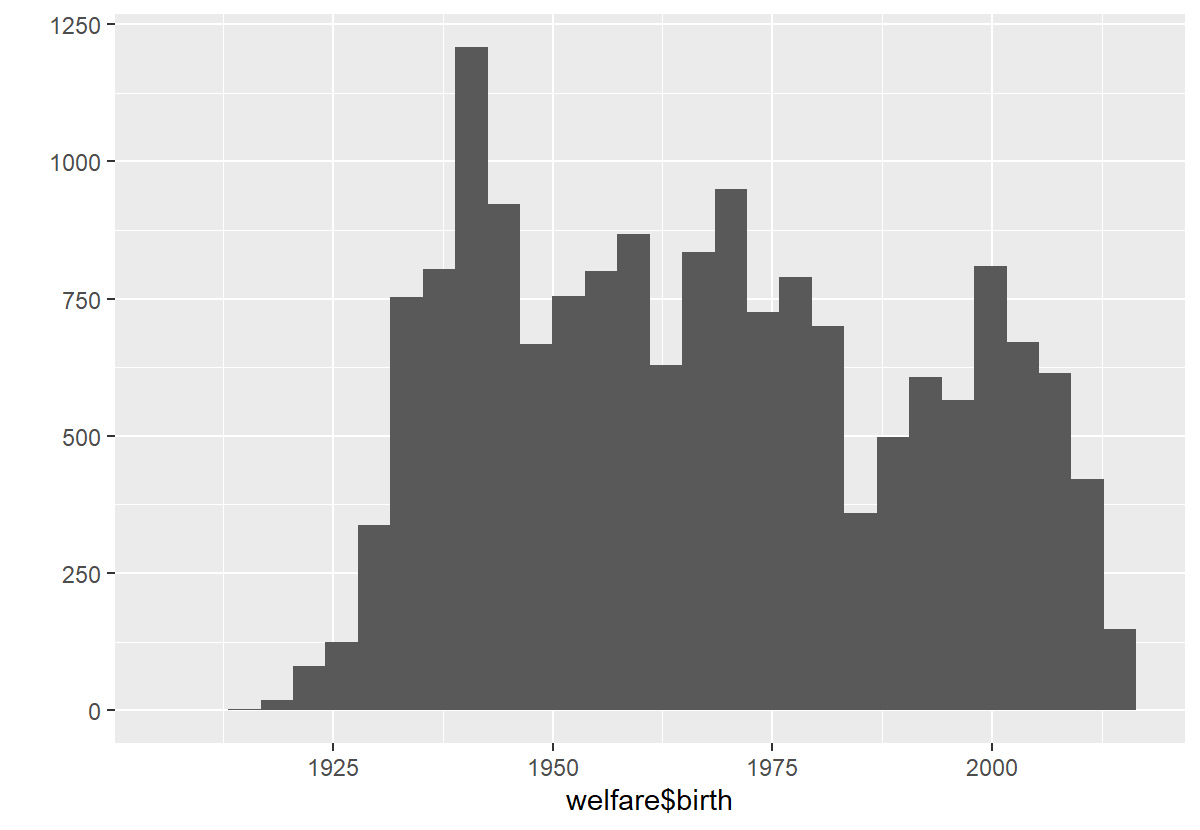
- 전처리
# 이상치 확인
summary(welfare$birth)
# 결측치 확인
table(is.na(welfare$birth))
- 이상치와 결측치가 없음 → 바로 파생변수 만드는 단계로 넘어감
- 태어난 연도를 이용해서 나이 변수 생성
- 2015년도에 조사가 진행됨 → 나이 = 2015 - 태어난 연도 + 1
welfare$age <- 2015 - welfare$birth + 1
summary(welfare$age)
qplot(welfare$age)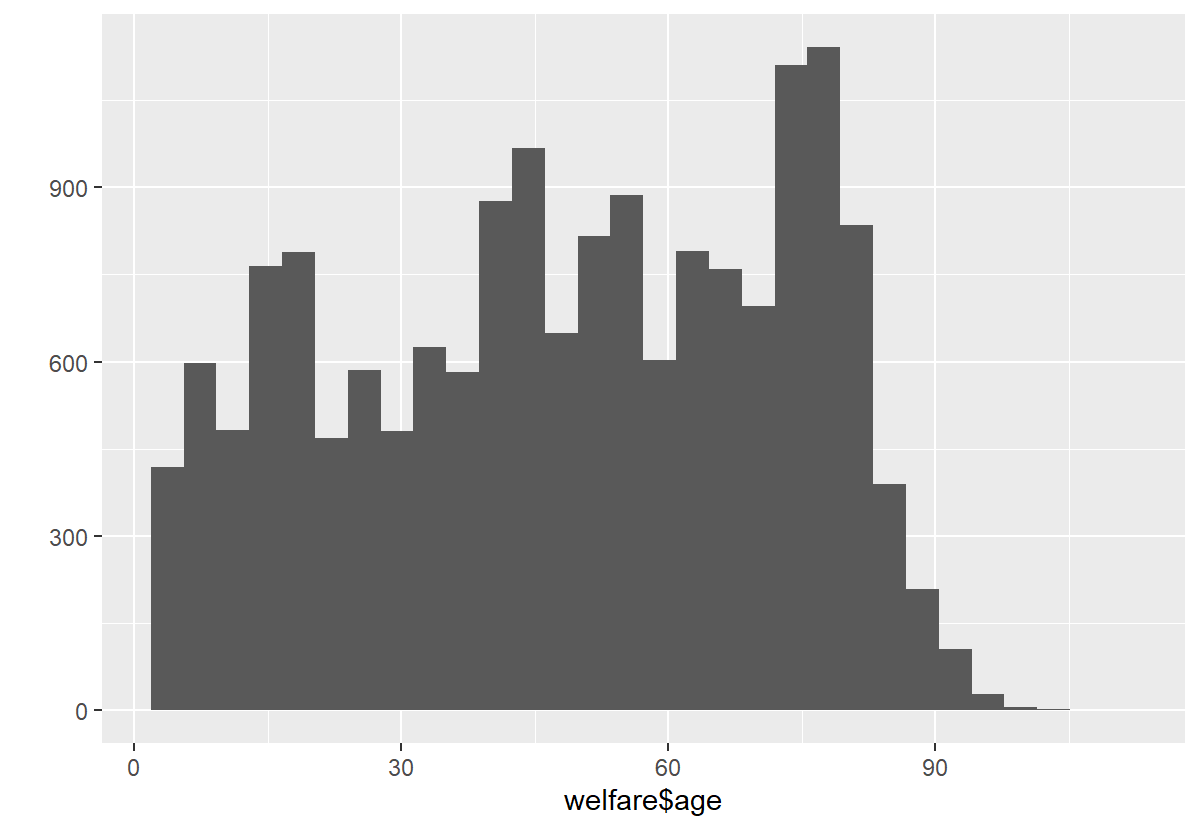
2. 변수 간 관계 분석하기
- 나이별 월급 평균표 만들기
age_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age) %>%
summarise(mean_income = mean(income))
head(age_income)
- 앞에서 만든 표로 선 그래프 만들기
ggplot(data = age_income, aes(x = age, y = mean_income)) + geom_line()
#04 연령대에 따른 월급 차이 분석
어떤 연령대의 월급이 가장 많은가?

1. 변수 검토 및 전처리
- 나이 변수를 이용해 연령대 변수 생성
welfare <- welfare %>%
mutate(ageg = ifelse(age < 30, "young", # age가 30 미만이면 "young"
ifelse(age <= 59, "middle", # age가 30 이상 59 이하이면 "middle"
"old"))) # age가 60 이상이면 "old"
# ageg 변수의 빈도수 확인 (각 연령대별 인원 수 출력)
table(welfare$ageg)
# ageg 변수의 분포를 막대 그래프로 시각화
qplot(welfare$ageg)

- 월급 변수 전처리 → 이미 완료
2. 변수 간 관계 분석
- 연령대별 월급 평균표 생성
ageg_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(ageg) %>%
summarise(mean_income = mean(income))
ageg_income
- 앞에 생성한 표를 이용해 그래프 만들기
ggplot(data = ageg_income, aes(x = ageg, y = mean_income)) + geom_col()

- 막대가 '초년, 중년, 노년' 나이 순으로 정렬되도록 설정
ggplot(data = ageg_income, aes(x = ageg, y = mean_income)) +
geom_col() + # 막대 그래프 생성
scale_x_discrete(limits = c("young", "middle", "old"))- scale_x_discrete()
- x축이 범주형(discrete) 데이터일 때 축을 조정하는 함수
- 연속형 변수에는 scale_x_continuous()를 사용하지만, 범주형 변수에는 scale_x_discrete()를 사용
- limits 파라미터: x축의 범주(레벨) 순서를 지정하는 역할

#05 연령대 및 성별 월급 차이 분석
성별 월급 차이는 연령대별로 다를까?

1. 전처리 → 앞에서 이미 완료
2. 변수 간 관계 분석
- 연령대 및 성별에 따른 월급 평균표 만들기
sex_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(ageg, sex) %>%
summarise(mean_income = mean(income))
sex_income
- 앞에서 만든 표를 이용해 그래프 만들기
- 막대가 연령대별로 표현되도록
- 막대로 성별에 따라 다른 색으로 표현되도록
ggplot(data = sex_income, aes(x = ageg, y = mean_income, fill = sex)) +
geom_col() +
scale_x_discrete(limits = c("young", "middle", "old"))
- 각 성별의 월급이 연령대 막대에 함께 표현되어 있음 → 차이를 비교하기 어려움
- position 파라미터를 "dodge"로 설정; 막대를 분리
# sex 변수를 char 데이터 타입으로 변환
sex_income$sex <- as.character(sex_income$sex)
# geom_col의 파라미터에 position = "dodge" 추가
ggplot(data = sex_income, aes(x = ageg, y = mean_income, fill = sex)) +
geom_col(position = "dodge") +
scale_x_discrete(limits = c("young", "middle", "old"))
- 나이 및 성별 월급 평균표를 생성
# 성별 연령별 월급 평균표 생성
sex_age <- welfare %>%
filter(!is.na(income)) %>%
group_by(age, sex) %>%
summarise(mean_income = mean(income))
head(sex_age)
- 생성한 표를 바탕으로 그래프 생성
sex_age$sex <- as.character(sex_age$sex)
ggplot(data = sex_age, aes(x = age, y = mean_income, col = sex)) + geom_line()

#06 직업별 월급 차이 분석
어떤 직업이 월급을 가장 많이 받을까?

1. 변수 검토 및 전처리
# 직업을 나타낸 code_job 변수 살펴보기
class(welfare$code_job)
table(welfare$code_job)
- 복지패널데이터에서 직업은 이름이 아니라 직업분류코드로 입력되어 있음
- 지금의 상태로는 해당 코드가 어떤 직업을 의미하는지 알 수 없음 → 직업분류코드를 이용해 직업 명칭 변수 만들기
2. 전처리
- 직업분류 코드 목록으로 직업의 명칭으로 된 변수 생성
- 직업분류코드 목록 데이터 프레임 생성
library(readxl) #readxl 패키지 로드: 엑셀 파일 불러옴
list_job <- read_excel("Koweps_Codebook.xlsx", col_names = T, sheet = 2)
#첫 행을 변수명으로 가져옴, 엑셀 파일의 두번째 시트에 있는 직업분류코드 목록 불러오도록 sheet = 2 지정
head(list_job)
dim(list_job)
## [1] 149 2 -> 직업이 149개로 분류됨
- job 변수를 welfare 에 결합 → using left_join()
welfare <- left_join(welfare, list_job, by = "code_job")
welfare %>%
filter(!is.na(code_job)) %>%
select(code_job, job) %>%
head(10)
3. 변수 간 관계 분석
- 직업별 월급 평균표 생성
job_income <- welfare %>%
filter(!is.na(job) & !is.na(income)) %>% # 직업이 없거나 월급이 없는 사람은 제외
group_by(job) %>%
summarise(mean_income = mean(income))
head(job_income)
- 월급을 내림차순으로 정렬, 상위 10개 추출
top10 <- job_income %>%
arrange(desc(mean_income)) %>% # 내림차순 정렬 (소득이 높은 직업부터 정렬)
head(10)
top10

- 앞에서 만든 표를 이용해 그래프 생성
ggplot(data = top10, aes(x = reorder(job, mean_income), y = mean_income)) + # job 변수를 mean_income 기준으로 정렬
geom_col() +
coord_flip() # 막대를 오른쪽으로 90도 회전
- 월급이 적인 직업들 알아보기: 월급이 하위 10위에 해당하는 직업 추출
bottom10 <- job_income %>%
arrange(mean_income) %>%
head(10)
bottom10
- 그래프 만들기
ggplot(data = bottom10, aes(x = reorder(job, -mean_income),
y = mean_income)) +
geom_col() +
coord_flip() +
ylim(0, 850)
#07 성별 직업 빈도 분석
성별에 따라 어떤 직업이 많을까?

1. '성별', '직업' 변수 전처리 → 이전에 완료
welfare$sex <- ifelse(welfare$sex == 1, "male", "female")
2. 변수 간 관계 분석하기
- 성별 직업 빈도표 만들기
# 남성 직업 빈도 상위 10개 추출
job_male <- welfare %>%
filter(!is.na(job) & sex == "male") %>%
group_by(job) %>%
summarise(n = n()) %>% # 각 직업별 인원 수(n) 계산
arrange(desc(n)) %>% # 인원 수(n)가 많은 순서대로 정렬 (내림차순)
head(10)
job_male
# 여성 작업 빈도 상위 10개 추출
job_female <- welfare %>%
filter(!is.na(job) & sex == "female") %>%
group_by(job) %>%
summarise(n = n()) %>% # 각 직업별 인원 수(n) 계산
arrange(desc(n)) %>% # 인원 수(n)가 많은 순서대로 정렬 (내림차순)
head(10)
job_female
- 성별 직업 빈도표를 이용해 그래프 만들기
# 남성 직업 빈도 상위 10개 직업
ggplot(data = job_male, aes(x = reorder(job, n), y = n)) + # job 변수를 n(빈도수) 기준으로 정렬
geom_col() +
coord_flip()

# 여성 직업 빈도 상위 10개 직업
ggplot(data = job_female, aes(x = reorder(job, n), y = n)) + # job 변수를 n(빈도수) 기준으로 정렬
geom_col() +
coord_flip()
- 결과
- 남성) 작물 재배 종사자, 자동차 운전원, 경영관련 사무원, 영업 종사자
- 여성) 작문 재배 종사자, 청소원 및 환경 미화원, 매장 판매 종사자, 제조 관련 단순 종사원
#08 종교 유무에 따른 이혼율 분석
종교가 있는 사람들이 종교가 없는 사람들보다 이혼을 덜 할까?

1. '종교' 변수 검토 및 전처리
class(welfare$religion)
table(welfare$religion)

- 값의 의미를 이해할 수 있도록 종교 유무에 따라 문자 부여
# 종교 유무 이름 부여
welfare$religion <- ifelse(welfare$religion == 1, "yes", "no")
table(welfare$religion)
qplot(welfare$religion)

2. '혼인 상태' 변수 검토 및 전처리
class(welfare$marriage)
table(welfare$marriage)
- 혼인 상태 변수값을 이용해 이혼 여부를 나타내는 파생변수 생성

# 이혼 여부 변수 만들기
welfare$group_marriage <- ifelse(welfare$marriage == 1, "marriage",
ifelse(welfare$marriage == 3, "divorce", NA))
table(welfare$group_marriage) # 파생변수 확인
table(is.na(welfare$group_marriage)
qplot(welfare$group_marriage)

3. 종교 유무에 따른 이혼율 분석하기
- 종교 유무에 따른 이혼율 표 생성
- 종교 유무 및 결혼 상태별로 빈도를 구함
- 각 종교 유무 집단의 전체 빈도로 나눠서 비율 구함
- 비율: round()를 통해 표현
# 방법 1
religion_marriage <- welfare %>%
filter(!is.na(group_marriage)) %>%
group_by(religion, group_marriage) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n), # tot_group과 pct라는 새로운 변수 2개를 추가
pct = round(n/tot_group*100, 1)) # 해당 그룹의 비율(%) 계산
religion_marriage- mutate(): 기존 데이터프레임에 새로운 변수를 추가하거나, 기존 변수를 변형할 때 사용
# 방법 2: dplyr 패키지의 count() 함수 사용
# count(): 집단별 빈도를 구하는 함수
religion_marriage <- welfare %>%
filter(!is.na(group_marriage)) %>%
count(religion, group_marriage) %>% # religion(종교 유무)과 group_marriage(혼인 상태)별 빈도수 계산
group_by(religion) %>%
mutate(pct = round(n/sum(n)*100, 1))
- 만든 표에서 이혼에 해당하는 값만 추출하여 이혼율 표 생성
# 이혼 추출
divorce <- religion_marriage %>%
filter(group_marriage == "divorce") %>%
select(religion, pct)
divorce
- 이혼율 표를 이용해 그래프 만들기
ggplot(data = divorce, aes(x = religion, y = pct)) + geom_col()
#09 지역별 연령대 비율 분석
어느 지역에 노인들이 많이 살고 있을까?

1. 변수 검토 및 전처리
class(welfare$code_region)
table(welfare$code_region)
- code_region 변수를 활용하여 welfare에 지역명 변수 추가

- 코드북의 내용을 참고해 지역 코드 목록 만들기
# 지역 코드 목록 만들기
list_region <- data.frame(code_region = c(1:7),
region = c("서울",
"수도권(인천/경기)",
"부산/경남/울산",
"대구/경북",
"대전/충남",
"강원/충북",
"광주/전남/전북/제주도"))
list_region
- welfare에 지역명 변수 추가
welfare <- left_join(welfare, list_region, by = "code_region")
welfare %>%
select(code_region, region) %>%
head
2. 전처리 → 연령대 변수 전처리는 앞에서 완료
3. 변수 간 관계 분석
- 지역별 연령대 비율표 만들기
- 지역 및 연령대별로 나눠 빈도를 구함
- 각 지역의 전체 빈도로 나눠 비율을 구함
region_ageg <- welfare %>%
group_by(region, ageg) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n), pct = round(n/tot_group*100, 2)) #소수점 둘째 자리까지 반올림
head(region_ageg)
- 만든 표를 이용해 그래프 만들기
- 연령대 비율 막대를 서로 다른 색으로 표현 → aes의 fill 파라미터에 ageg 지정
- coord_flip() 추가 → 그래프를 오른쪽으로 회전
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) +
geom_col() +
coord_flip()
- 노년층 비율이 높은 순으로 막대 정렬
- 노년층 비율 순으로 지역명이 정렬된 변수 생성 → 앞에서 만든 표를 노년층 비율순으로 정렬한 후 지역명만 추출
# 노년층 비율 내림차순 정렬
list_order_old <- region_ageg %>%
filter(ageg == "old") %>%
arrange(pct)
list_order_old
# 지역명 순서 변수 만들기
order <- list_order_old$region
order
- order 변수(지역명이 노년층 비율 순으로 정렬된 변수) 를 이용해 그래프 만들기
ggplot(data = region_ageg, aes(x = region, y = pct, fill = ageg)) +
geom_col() +
coord_flip() +
scale_x_discrete(limits = order) # x축에 표시할 범주형 변수의 수준(level) 순서를 order로 지정
- 막대 색깔을 '초년, 중년, 노년'의 연령대 순으로 나열되도록 설정
- 막대 색깔을 순서대로 나열 → fill 파라미터에 지정할 변수의 범주 (levels) 순서 지정
- 다시 그래프 생성
- ageg 변수를 factor 타입으로 변경
- factor() : 범주형 데이터(factor)를 생성하거나 기존 변수의 범주(level) 순서를 지정하는 함수
- level 파라미터 활용하여 순서 지정
region_ageg$ageg <- factor(region_ageg$ageg,
level = c("old", "middle", "young"))
class(region_ageg$ageg)
levels(region_ageg$ageg)
# 그래프 생성 코드 다시 실행
ggplot(data = region_ageg, aes(x=region, y = pct, fill = ageg)) +
geom_col() +
coord_flip() +
scale_x_discrete(limits = order)
'Programming Languages > R' 카테고리의 다른 글
| [심화] R performance 패키지 (0) | 2025.03.04 |
|---|---|
| 5. 텍스트 마이닝 (0) | 2025.02.27 |
| 4. 그래프 만들기 (ggplot2) (0) | 2025.02.17 |
| 3. 데이터 가공, 정제하기 (0) | 2025.02.13 |
| 2. 데이터 프레임, 데이터 불러오기, 데이터 분석의 기초 (0) | 2025.02.06 |



